Configuring Crawl Jobs
Basic Job Settings
Crawl settings are configured by editing the job’s primary configuration file, usually crawler-beans.cxml or
crawler-beans.groovy.
Profiles
A profile is a non-launchable job template. To create one from the web interface, open an existing job, choose
Copy Job, enter the new profile name, check as profile, and submit the form. Heritrix treats jobs
whose primary configuration filename starts with profile- as profiles. They can be built for validation, but not
launched directly.
Profiles appear in the create job profile selector by their job name. Choosing one creates a new launchable job
by copying the profile and removing the profile- prefix from the primary configuration filename.
The built-in defaults can be overridden by creating a profile with the same name as the built-in profile.
Crawl Limits
In addition to limits imposed on the scope of the crawl it is possible to enforce arbitrary limits on the duration and extent of the crawl with the following settings:
- maxBytesDownload
Stop the crawl after a fixed number of bytes have been downloaded. Zero means unlimited.
- maxDocumentDownload
Stop the crawl after downloading a fixed number of documents. Zero means unlimited.
- maxTimeSeconds
Stop the crawl after a certain number of seconds have elapsed. Zero means unlimited. For reference there are 3600 seconds in an hour and 86400 seconds in a day.
To set these values modify the CrawlLimitEnforcer bean.
<bean id="crawlLimitEnforcer" class="org.archive.crawler.framework.CrawlLimitEnforcer">
<property name="maxBytesDownload" value="100000000" />
<property name="maxDocumentsDownload" value="100" />
<property name="maxTimeSeconds" value="10000" />
</bean>
crawlLimitEnforcer(CrawlLimitEnforcer) {
maxBytesDownload = 100000000
maxDocumentsDownload = 100
maxTimeSeconds = 10000
}
Note
These are not hard limits. Once one of these limits is hit it will trigger a graceful termination of the crawl job. URIs already being crawled will be completed. As a result the set limit will be exceeded by some amount.
maxToeThreads
The maximum number of toe threads to run.
If running a domain crawl smaller than 100 hosts, a value approximately twice the number of hosts should be enough. Values larger then 150-200 are rarely worthwhile unless running on machines with exceptional resources.
<bean id="crawlController" class="org.archive.crawler.framework.CrawlController">
<property name="maxToeThreads" value="50" />
</bean>
crawlController(CrawlController) {
maxToeThreads = 50
}
metadata.operatorContactUrl
The URI of the crawl initiator. This setting gives the administrator of a crawled host a URI to refer to in case of problems.
<bean id="simpleOverrides" class="org.springframework.beans.factory.config.PropertyOverrideConfigurer">
<property name="properties">
<value>
metadata.operatorContactUrl=http://www.archive.org
metadata.jobName=basic
metadata.description=Basic crawl starting with useful defaults
</value>
</property>
</bean>
simpleOverrides(PropertyOverrideConfigurer) {
properties = '''
metadata.operatorContactUrl=http://www.archive.org
metadata.jobName=basic
metadata.description=Basic crawl starting with useful defaults
'''
}
Robots.txt Honoring Policy
The valid values of “robotsPolicyName” are:
- obey
Obey robots.txt directives and nofollow robots meta tags
- classic
Same as “obey”
- robotsTxtOnly
Obey robots.txt directives but ignore robots meta tags
- ignore
Ignore robots.txt directives and robots meta tags
<bean id="metadata" class="org.archive.modules.CrawlMetadata" autowire="byName">
...
<property name="robotsPolicyName" value="obey"/>
...
</bean>
metadata(CrawlMetadata) { bean ->
bean.autowire = 'byName'
// ...
robotsPolicyName = 'obey'
// ...
}
Note
Heritrix supports RFC 9309 path wildcards (*, $) in robots.txt rules.
The only supported value for robots meta tags is “nofollow” which will cause the HTML extractor to stop processing and ignore all links (including embeds like images and stylesheets).
<meta name="robots" content="nofollow"/>
Obeying “rel=nofollow” on individual links is configured separately as obeyRelNoFollow on ExtractorHTML.
Crawl Scope
The crawl scope defines the set of possible URIs that can be captured by a crawl. These URIs are determined by DecideRules, which work in combination to limit or expand the set of crawled URIs. Each DecideRule, when presented with an object (most often a URI of some form) responds with one of three decisions:
- ACCEPT
the object is ruled in
- REJECT
the object is ruled out
- PASS
the rule has no opinion; retain the previous decision
A URI under consideration begins with no assumed status. Each rule is applied in turn to the candidate URI. If the rule decides ACCEPT or REJECT, the URI’s status is set accordingly. After all rules have been applied, the URI is determined to be “in scope” if its status is ACCEPT. If its status is REJECT it is discarded.
We suggest starting with the rules in our recommended default configurations and performing small test crawls with those rules. Understand why certain URIs are ruled in or ruled out under those rules. Then make small individual changes to the scope to achieve non-default desired effects. Creating a new ruleset from scratch can be difficult and can easily result in crawls that can’t make the usual minimal progress that other parts of the crawler expect. Similarly, making many changes at once can obscure the importance of the interplay and ordering of the rules.
Decide Rules
- DecideRule: AcceptDecideRule
This DecideRule accepts any URI.
- DecideRule: ContentLengthDecideRule
This DecideRule accepts a URI if the content-length is less than the threshold. The default threshold is 2^63, meaning any document will be accepted.
- DecideRule: PathologicalPathDecideRule
This DecideRule rejects any URI that contains an excessive number of identical, consecutive path-segments. For example,
http://example.com/a/a/a/a/a/foo.html.- DecideRule: PredicatedDecideRule
This DecideRule applies a configured decision only if a test evaluates to true.
- DecideRule: ExternalGeoLocationDecideRule
This DecideRule accepts a URI if it is located in a particular country.
- DecideRule: FetchStatusDecideRule
This DecideRule applies the configured decision to any URI that has a fetch staus equal to the “target-status” setting.
- DecideRule: HasViaDecideRule
This DecideRule applies the configured decision to any URI that has a “via.” A via is any URI that is a seed or some kind of mid-crawl addition.
- DecideRule: HopCrossesAssignmentLevelDomainDecideRule
This DecideRule applies the configured decision to any URI that differs in the portion of its hostname/domain that is assigned/sold by registrars. The portion is referred to as the “assignment-level-domain” (ALD).
- DecideRule: IdenticalDigestDecideRule
This DecideRule applies the configured decision to any URI whose prior-history content-digest matches the latest fetch.
- DecideRule: MatchesListRegexDecideRule
This DecideRule applies the configured decision to any URI that matches the supplied regular expressions.
- DecideRule: NotMatchesListRegexDecideRule
This DecideRule applies the configured decision to any URI that does not match the supplied regular expressions.
- DecideRule: MatchesRegexDecideRule
This DecideRule applies the configured decision to any URI that matches the supplied regular expression.
- DecideRule: ClassKeyMatchesRegexDecideRule
This DecideRule applies the configured decision to any URI class key that matches the supplied regular expression. A URI class key is a string that specifies the name of the Frontier queue into which a URI should be placed.
- DecideRule: ContentTypeMatchesRegexDecideRule
This DecideRule applies the configured decision to any URI whose content-type is present and matches the supplied regular expression. The regular expression must match the full content-type sequence. Ex.:
s/application/javascript;charset=UTF-8/^application\/javascript.*$/g;s/text/html/^.*\/html.*$/g- DecideRule: ContentTypeNotMatchesRegexDecideRule
This DecideRule applies the configured decision to any URI whose content-type does not match the supplied regular expression.
- DecideRule: FetchStatusMatchesRegexDecideRule
This DecideRule applies the configured decision to any URI that has a fetch status that matches the supplied regular expression.
- DecideRule: FetchStatusNotMatchesRegexDecideRule
This DecideRule applies the configured decision to any URI that has a fetch status that does not match the suppllied regular expression.
- DecideRule: HopsPathMatchesRegexDecideRule
This DecideRule applies the configured decision to any URI whose “hops-path” matches the supplied regular expression. The hops-path is a string that consists of characters representing the path that was taken to access the URI. An example of a hops-path is “LLXE”.
- DecideRule: MatchesFilePatternDecideRule
This DecideRule applies the configured decision to any URI whose suffix matches the supplied regular expression.
- DecideRule: NotMatchesFilePatternDecideRule
This DecideRule applies the configured decision to any URI whose suffix does not match the supplied regular expression.
- DecideRule: NotMatchesRegexDecideRule
This DecideRule applies the configured decision to any URI that does not match the supplied regular expression.
- DecideRule: NotExceedsDocumentLengthThresholdDecideRule
This DecideRule applies the configured decision to any URI whose content-length does not exceed the configured threshold. The content-length comes from either the HTTP header or the actual downloaded content length of the URI. As of Heritrix 3.1, this rule has been renamed to ResourceNoLongerThanDecideRule.
- DecideRule: ExceedsDocumentLengthThresholdDecideRule
This DecideRule applies the configured decision to any URI whose content length exceeds the configured threshold. The content-length comes from either the HTTP header or the actual downloaded content length of the URI. As of Heritrix 3.1, this rule has been renamed to ResourceLongerThanDecideRule.
- DecideRule: SurtPrefixedDecideRule
This DecideRule applies the configured decision to any URI (expressed in SURT form) that begins with one of the prefixes in the configured set. This DecideRule returns true when the prefix of a given URI matches any of the listed SURTs. The list of SURTs may be configured in different ways: the surtsSourceFile parameter specifies a file to read the SURTs list from. If seedsAsSurtPrefixes parameter is set to true, SurtPrefixedDecideRule adds all seeds to the SURTs list. If alsoCheckVia property is set to true (default false), SurtPrefixedDecideRule will also consider Via URIs in the match. As of Heritrix 3.1, the “surtsSource” parameter may be any ReadSource, such as a ConfigFile or a ConfigString. This gives the SurtPrefixedDecideRule the flexibility of the TextSeedModule bean’s “textSource” property.
- DecideRule: NotSurtPrefixedDecideRule
This DecideRule applies the configured decision to any URI (expressed in SURT form) that does not begin with one of the prefixes in the configured set.
- DecideRule: OnDomainsDecideRule
This DecideRule applies the configured decision to any URI that is in one of the domains of the configured set.
- DecideRule: NotOnDomainsDecideRule
This DecideRule applies the configured decision to any URI that is not in one of the domains of the configured set.
- DecideRule: OnHostsDecideRule
This DecideRule applies the configured decision to any URI that is in one of the hosts of the configured set.
- DecideRule: NotOnHostsDecideRule
This DecideRule applies the configured decision to any URI that is not in one of the hosts of the configured set.
- DecideRule: ScopePlusOneDecideRule
This DecideRule applies the configured decision to any URI that is one level beyond the configured scope.
- DecideRule: TooManyHopsDecideRule
This DecideRule rejects any URI whose total number of hops is over the configured threshold.
- DecideRule: TooManyPathSegmentsDecideRule
This DecideRule rejects any URI whose total number of path-segments is over the configured threshold. A path-segment is a string in the URI separated by a “/” character, not including the first “//”.
- DecideRule: TransclusionDecideRule
This DecideRule accepts any URI whose path-from-seed ends in at least one non-navlink hop. A navlink hop is represented by an “L”. Also, the number of non-navlink hops in the path-from-seed cannot exceed the configured value.
- DecideRule: PrerequisiteAcceptDecideRule
This DecideRule accepts all “prerequisite” URIs. Prerequisite URIs are those whose hops-path has a “P” in the last position.
- DecideRule: RejectDecideRule
This DecideRule rejects any URI.
- DecideRule: ScriptedDecideRule
This DecideRule applies the configured decision to any URI that passes the rules test of a JSR-223 script. The script source must be a one-argument function called decisionFor.” The function returns the appropriate DecideResult. Variables available to the script include object (the object to be evaluated, such as a URI), “self” (the ScriptDecideRule instance), and context (the crawl’s ApplicationContext, from which all named crawl beans are reachable).
- DecideRule: SeedAcceptDecideRule
This DecideRule accepts all “seed” URIs (those for which isSeed is true).
DecideRuleSequence Logging
Enable FINEST logging on the class org.archive.crawler.deciderules.DecideRuleSequence to watch each
DecideRule’s evaluation of the processed URI. This can be done in the logging.properties file:
org.archive.modules.deciderules.DecideRuleSequence.level = FINEST
in conjunction with the -Dsysprop VM argument,
-Djava.util.logging.config.file=/path/to/heritrix3/dist/src/main/conf/logging.properties
Frontier
Politeness
A combination of several settings control the politeness of the Frontier. It is important to note that at any given time only one URI from any given host is processed. The following politeness rules impose additional wait time between the end of processing one URI and the start of the next one.
- delayFactor
This setting imposes a delay between the fetching of URIs from the same host. The delay is a multiple of the amount of time it took to fetch the last URI downloaded from the host. For example, if it took 800 milliseconds to fetch the last URI from a host and the
delayFactoris 5 (a very high value), then the Frontier will wait 4000 milliseconds (4 seconds) before allowing another URI from that host to be processed.- maxDelayMs
This setting imposes a maximum upper limit on the wait time created by the
delayFactor. If set to 1000 milliseconds, then the maximum delay between URI fetches from the same host will never exceed this value.- minDelayMs
This setting imposes a minimum limit on politeness. It takes precedence over the value calculated by the
delayFactor. For example, the value ofminDelayMscan be set to 100 milliseconds. If thedelayFactoronly generates a 20 millisecond wait, the value ofminDelayMswill override it and the URI fetch will be delayed for 100 milliseconds.
<bean id="disposition" class="org.archive.crawler.postprocessor.DispositionProcessor">
<property name="delayFactor" value="5.0" />
<property name="maxDelayMs" value="30000" />
<property name="minDelayMs" value="3000" />
</bean>
disposition(DispositionProcessor) {
delayFactor = 5.0
maxDelayMs = 30000
minDelayMs = 3000
}
Retry Policy
The Frontier can be used to limit the number of fetch retries for a URI. Heritrix will retry fetching a URI because the initial fetch error may be a transitory condition.
- maxRetries
This setting limits the number of fetch retries attempted on a URI due to transient errors.
- retryDelaySeconds
This setting determines how long the wait period is between retries.
<bean id="frontier" class="org.archive.crawler.frontier.BdbFrontier">
<property name="retryDelaySeconds" value="900" />
<property name="maxRetries" value="30" />
</bean>
frontier(BdbFrontier) {
retryDelaySeconds = 900
maxRetries = 30
}
Bandwidth Limits
The Frontier allows the user to limit bandwidth usage. This is done by holding back URIs when bandwidth usage has exceeded certain limits. Because bandwidth usage limitations are calculated over a period of time, there can still be spikes in usage that greatly exceed the limits.
- maxPerHostBandwidthUsageKbSec
This setting limits the maximum bandwidth to use for any host. This setting limits the load placed by Heritrix on the host. It is therefore a politeness setting.
<bean id="disposition" class="org.archive.crawler.postprocessor.DispositionProcessor"> <property name="maxPerHostBandwidthUsageKbSec" value="500" /> </bean>
disposition(DispositionProcessor) { maxPerHostBandwidthUsageKbSec = 500 }
Extractor Parameters
The Frontier’s behavior with regard to link extraction can be controlled by the following parameters.
- extract404s
This setting allows the operator to avoid extracting links from 404 (Not Found) pages. The default is true, which maintains the pre-3.1 behavior of extracting links from 404 pages.
<bean id="frontier" class="org.archive.crawler.frontier.BdbFrontier"> <property name="extract404s" value="true" /> </bean>
frontier(BdbFrontier) { extract404s = true }
- extractIndependently
This setting encourages extractor processors to always perform their best-effort extraction, even if a previous extractor has marked a URI as already-handled. Set the value to true for best-effort extraction. The default is false, which maintains the pre-3.1 behavior.
<bean id="frontier" class="org.archive.crawler.frontier.BdbFrontier"> <property name="extractIndependently" value="false" /> </bean>
frontier(BdbFrontier) { extractIndependently = false }
Sheets (Site-specific Settings)
Sheets provide the ability to replace default settings on a per domain basis. Sheets are collections of overrides. They contain alternative values for object properties that should apply in certain contexts. The target is specified as an arbitrarily-long property-path, which is a string describing how to access the property starting from a beanName in a BeanFactory.
Sheets allow settings to be overlaid with new values that apply by top level domains (com, net, org, etc), by second-level domains (yahoo.com, archive.org, etc.), by subdomains (crawler.archive.org, tech.groups.yahoo.com, etc.) , and leading URI paths (directory.google.com/Top/Computers/, etc.). There is no limit for how long the domain/path prefix which specifies overlays can go; the SURT Prefix syntax is used.
Creating a new sheet involves configuring the crawler-beans.cxml file, which contains the Spring configuration of
a job.
For example, if you have explicit permission to crawl certain domains without the usual polite rate-limiting, then a Sheet can be used to create a less polite crawling policy that is associated with a few such target domains. The configuration of such a Sheet for the domains example.com and example1.com are shown below. This example allows up to 5 parallel outstanding requests at a time (rather than the default 1), and eliminates any usual pauses between requests.
Warning
Unless a target site has given you explicit permission to crawl extra-aggressively, the typical Heritrix defaults, which limit the crawler to no more than one outstanding request at a time, with multiple-second waits between requests, and longer waits when the site is responding more slowly, are the safest course. Less-polite crawling can result in your crawler being blocked entirely by webmasters.
Finally, even with permission, be sure your crawler’s User-Agent string includes a link to valid crawl-operator contact information so you can be alerted to, and correct, any unintended side-effects.
<bean id="sheetOverlaysManager" autowire="byType" class="org.archive.crawler.spring.SheetOverlaysManager">
</bean>
<bean class='org.archive.crawler.spring.SurtPrefixesSheetAssociation'>
<property name='surtPrefixes'>
<list>
<value>http://(com,example,www,)/</value>
<value>http://(com,example1,www,)/</value>
</list>
</property>
<property name='targetSheetNames'>
<list>
<value>lessPolite</value>
</list>
</property>
</bean>
<bean id='lessPolite' class='org.archive.spring.Sheet'>
<property name='map'>
<map>
<entry key='disposition.delayFactor' value='0.0'/>
<entry key='disposition.maxDelayMs' value='0'/>
<entry key='disposition.minDelayMs' value='0'/>
<entry key='queueAssignmentPolicy.parallelQueues' value='5'/>
</map>
</property>
</bean>
sheetOverlaysManager(SheetOverlaysManager) { bean ->
bean.autowire = 'byType'
}
lessPoliteAssociation(SurtPrefixesSheetAssociation) {
surtPrefixes = [
'http://(com,example,www,)/',
'http://(com,example1,www,)/',
]
targetSheetNames = [
'lessPolite',
]
}
lessPolite(Sheet) {
map = [
'disposition.delayFactor': '0.0',
'disposition.maxDelayMs': '0',
'disposition.minDelayMs': '0',
'queueAssignmentPolicy.parallelQueues': '5',
]
}
Other Protocols
In addition to HTTP/1.0 Heritrix can be configured to fetch resources using several other internet protocols.
FTP
Heritrix supports crawling FTP sites. Seeds should be added
in the following format: `ftp://sftp.example.org/directory.
The FetchFTP bean needs to be defined:
<bean id="fetchFTP" class="org.archive.modules.fetcher.FetchFTP">
<!-- <property name="digestAlgorithm" value="sha1" /> -->
<!-- <property name="digestContent" value="true" /> -->
<!-- <property name="extractFromDirs" value="true" /> -->
<!-- <property name="extractParent" value="true" /> -->
<!-- <property name="maxFetchKBSec" value="0" /> -->
<!-- <property name="maxLengthBytes" value="0" /> -->
<!-- <property name="password" value="password" /> -->
<!-- <property name="soTimeoutMs" value="" /> -->
<!-- <property name="timeoutSeconds" value="" /> -->
<!-- <property name="username" value="anonymous" /> -->
</bean>
import org.archive.modules.fetcher.FetchFTP
fetchFTP(FetchFTP) {
// digestAlgorithm = 'sha1'
// digestContent = true
// extractFromDirs = true
// extractParent = true
// maxFetchKBSec = 0
// maxLengthBytes = 0
// password = 'password'
// soTimeoutMs = 0
// timeoutSeconds = 0
// username = 'anonymous'
}
and added to the FetchChain:
<bean id="fetchProcessors" class="org.archive.modules.FetchChain">
<property name="processors">
<list>...
<ref bean="fetchFTP"/>
...
</list>
</property>
</bean>
fetchProcessors(FetchChain) {
processors = [
// ...
ref('fetchFTP'),
// ...
]
}
HTTP/2
To use HTTP/2 the FetchHTTP bean should replaced with FetchHTTP2:
<bean id="fetchHTTP2" class="org.archive.modules.fetcher.FetchHTTP2">
<!-- <property name="digestAlgorithm" value="sha1" /> -->
<!-- <property name="httpProxyHost" value="" /> -->
<!-- <property name="httpProxyPort" value="" /> -->
<!-- <property name="maxFetchKBSec" value="0" /> -->
<!-- <property name="maxLengthBytes" value="0" /> -->
<!-- <property name="socksProxyHost" value="" /> -->
<!-- <property name="socksProxyPassword" value="" /> -->
<!-- <property name="socksProxyPort" value="" /> -->
<!-- <property name="socksProxyUsername" value="" /> -->
<!-- <property name="timeoutSeconds" value="20" /> -->
<!-- <property name="useHTTP2" value="true" /> -->
<!-- <property name="useHTTP3" value="false" /> -->
<!-- <property name="userAgentProvider" value="" /> -->
</bean>
import org.archive.modules.fetcher.FetchHTTP2
fetchHTTP2(FetchHTTP2) {
// digestAlgorithm = 'sha1'
// httpProxyHost = ''
// httpProxyPort = 0
// maxFetchKBSec = 0
// maxLengthBytes = 0
// socksProxyHost = ''
// socksProxyPassword = ''
// socksProxyPort = 0
// socksProxyUsername = ''
// timeoutSeconds = 20
// useHTTP2 = true
// useHTTP3 = false
// userAgentProvider = ''
}
FetchHTTP2 will use HTTP/1.1 for non-https URLs and for servers that do not support HTTP/2. Requests that used HTTP/2
will be annotated with h2 in the crawl log and WARC-Protocol header.
Note that FetchHTTP2 currently only supports a limited subset of the FetchHTTP options.
Note
The WARC standard (as of version 1.1) does not specify how to record HTTP/2 or 3 messages. FetchHTTP2 does not record the original on-the-wire HTTP messages but instead a simplified HTTP/1.1 representation without transfer encoding.
If you want to stay within the bounds of the base WARC standard without extensions, or want to ensure the exact bytes of the HTTP network message are recorded, you may prefer to use FetchHTTP.
HTTP/3
HTTP/3 support is experimental and is not enabled by default. First replace FetchHTTP with FetchHTTP2 as described
above and then enable the useHTTP3 property:
<bean id="fetchHttp2" class="org.archive.modules.fetcher.FetchHTTP2">
<property name="useHTTP3" value="true">
</bean>
fetchHttp2(FetchHTTP2) {
useHTTP3 = true
}
An appropriate version of the jetty-quiche-native jar also needs to be placed in Heritrix’s lib directory. To find out
which version you need, build a job with useHTTP3 enabled and a warning will be logged to the job log with a download
link.
HTTP/3 requests will only be sent after a server first responds with an Alt-Svc header. Requests that used HTTP/3 will
be annotated with h3 in the crawl log and WARC-Protocol header.
SFTP
An optional fetcher for SFTP is provided. Seeds should
be added in the following format:sftp://sftp.example.org/directory.
The FetchSFTP bean needs to be defined:
<bean id="fetchSFTP" class="org.archive.modules.fetcher.FetchSFTP">
<!-- <property name="digestAlgorithm" value="sha1" /> -->
<!-- <property name="digestContent" value="true" /> -->
<!-- <property name="extractFromDirs" value="true" /> -->
<!-- <property name="extractParent" value="true" /> -->
<!-- <property name="maxFetchKBSec" value="0" /> -->
<!-- <property name="maxLengthBytes" value="0" /> -->
<!-- <property name="password" value="password" /> -->
<!-- <property name="soTimeoutMs" value="" /> -->
<!-- <property name="timeoutSeconds" value="" /> -->
<!-- <property name="username" value="anonymous" /> -->
</bean>
import org.archive.modules.fetcher.FetchSFTP
fetchSFTP(FetchSFTP) {
// digestAlgorithm = 'sha1'
// digestContent = true
// extractFromDirs = true
// extractParent = true
// maxFetchKBSec = 0
// maxLengthBytes = 0
// password = 'password'
// soTimeoutMs = 0
// timeoutSeconds = 0
// username = 'anonymous'
}
and added to the FetchChain:
<bean id="fetchProcessors" class="org.archive.modules.FetchChain">
<property name="processors">
<list>
...
<ref bean="fetchSFTP"/>
...
</list>
</property>
</bean>
fetchProcessors(FetchChain) {
processors = [
// ...
ref('fetchSFTP'),
// ...
]
}
WHOIS
An optional fetcher for domain WHOIS data is provided. A small set of well-established WHOIS servers are preconfigured. The fetcher uses an ad-hoc/intuitive interpretation of a ‘whois:’ scheme URI.
Define the fetchWhois bean:
<bean id="fetchWhois" class="org.archive.modules.fetcher.FetchWhois">
<property name="specialQueryTemplates">
<map>
<entry key="whois.verisign-grs.com" value="domain %s" />
<entry key="whois.arin.net" value="z + %s" />
<entry key="whois.denic.de" value="-T dn %s" />
</map>
</property>
</bean>
fetchWhois(FetchWhois) {
specialQueryTemplates = [
'whois.verisign-grs.com': 'domain %s',
'whois.arin.net': 'z + %s',
'whois.denic.de': '-T dn %s',
]
}
and add it to the FetchChain:
<bean id="fetchProcessors" class="org.archive.modules.FetchChain">
<property name="processors">
<list>
...
<ref bean="fetchWhois"/>
...
</list>
</property>
</bean>
fetchProcessors(FetchChain) {
processors = [
// ...
ref('fetchWhois'),
// ...
]
}
To configure a whois seed, enter the seed in the following format: whois://hostname/path. For example,
whois://archive.org. The whois fetcher will attempt to resolve each host that the crawl encounters using the
topmost assigned domain and the ip address of the url crawled. So if you crawl http://www.archive.org/details/texts,
the whois fetcher will attempt to resolve whois:archive.org and whois:207.241.224.2.
At this time, whois functionality is experimental. The fetchWhois bean is commented out in the default profile.
Modifying a Running Job
While changing a job’s XML configuration normally requires relaunching it, some settings can be modified while the crawl is running. This is done through the Browse Beans or the Scripting Console link on the job page. The Bean Browser allows you to edit runtime properties of beans. You can also use the scripting console to programmatically edit a running job.
If changing a non-atomic value, it is a good practice to pause the crawl prior to making the change, as some modifications to composite configuration entities may not occur in a thread-safe manner. An example of a non-atomic change is adding a new Sheet.
Browse Beans
The WUI provides a way to view and edit the Spring beans that make up a crawl configuration. It is important to note
that changing the crawl configuration using the Bean Browser will not update the crawler-beans.cxml file. Thus,
changing settings with the Bean Browser is not permanent. The Bean Browser should only by used to change the settings
of a running crawl. To access the Bean Browser click on the Browse Beans link from the jobs page. The hierarchy of
Spring beans will be displayed.
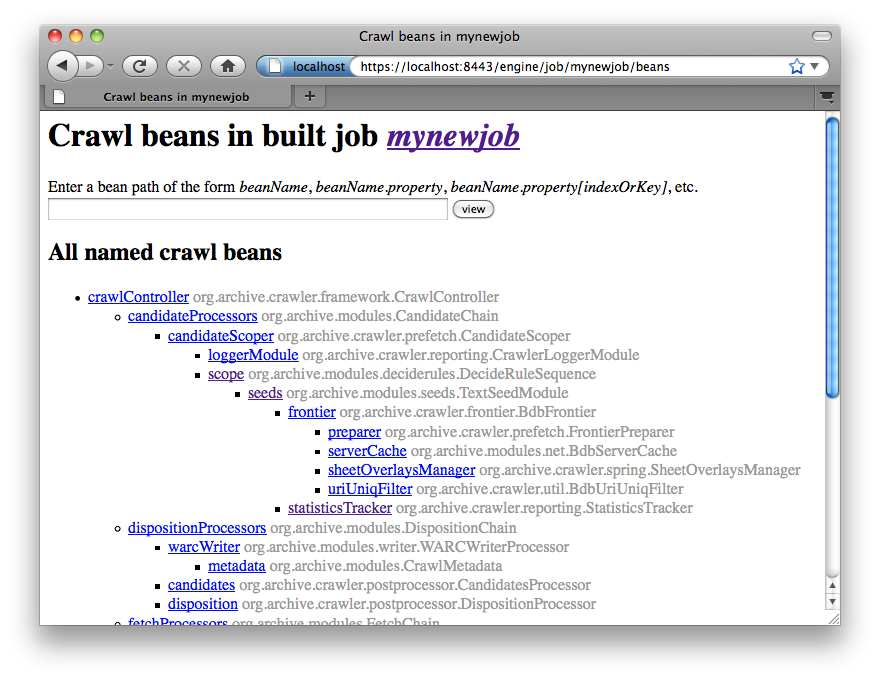
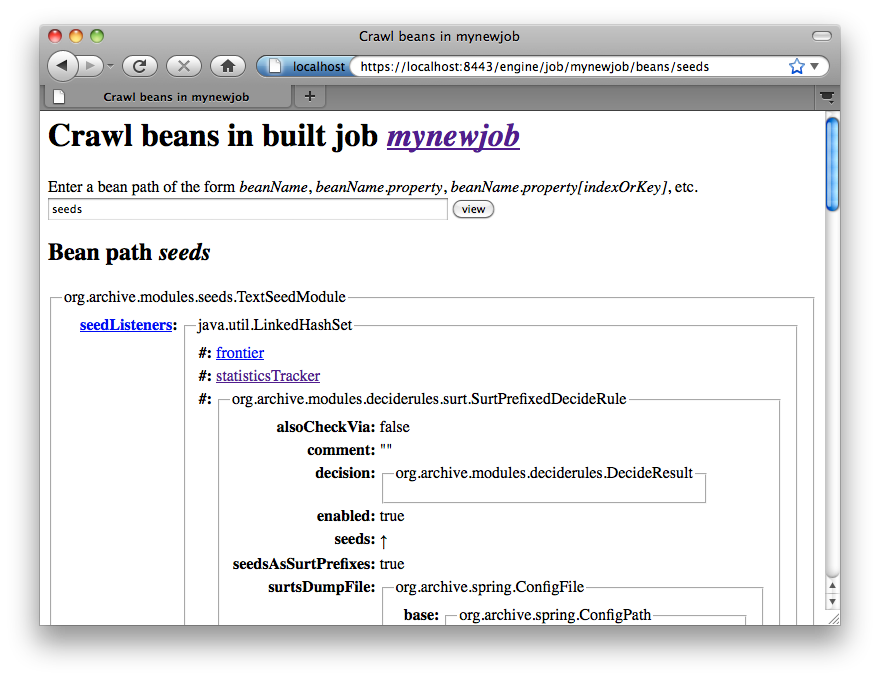
You can drill down on individual beans by clicking on them. The example below shows the display after clicking on the seeds bean.
Scripting Console
[This section to be written. For now see the Heritrix3 Useful Scripts wiki page.]
Configuring HTTP Proxies
There are two options to specify a proxy for crawling.
The command line options --proxy-host and --proxy-port can be used to define a proxy for all jobs.
If only the --proxy-host option is given, a default value of 8000 is used for the proxy port.
These proxy settings are also used when connecting to a “DNS-over-HTTP” server
(see the section on DNS-over-HTTP below).
Alternatively one can define a per-job proxy via a the httpProxyHost and httpProxyPort properties of the
fetchHttp bean. These settings, if both defined, will overwrite the global options. These setting also allow for
a user and password in the httpProxyUser and httpProxyPassword properties, which the global options do not
support, due to incompatibilities of the different supported Java versions.
Also the optional “SOCKS5” proxy documented in the next section is used on a per-job basis; there are currently no global options to define it.
Configuring SOCKS5 Proxy
An optional configuration value to route Heritrix crawler traffic through a SOCKS5 proxy. This will override any set HTTP proxy configuration. It is facilitated by extending the org.archive.modules.fetcher.FetchHTTP bean with socksProxyHost and socksProxyPort values, as in the example below:
<bean class="org.archive.modules.fetcher.FetchHTTP" id="fetchHttp">
<!-- ... -->
<property name="socksProxyHost" value="127.0.0.1"/>
<property name="socksProxyPort" value="24000"/>
</bean>
fetchHttp(FetchHTTP) {
// ...
socksProxyHost = '127.0.0.1'
socksProxyPort = 24000
}
Configuring DNS over HTTP (DoH)
If the local DNS on the server running Heritrix is not able to resolve the DNS names of the crawled sites, e.g. because the server is sitting behind an enterprise firewall and can only resolve names of the local network, then using DNS-over-HTTP (DoH) might be an alternative to fetch DNS information.
To activate this, one needs to set the dnsOverHttpServer setting of the fetchDns bean to the URL of an DoH server.
If one has configured a global proxy via the --proxy-host and --proxy-port command line options,
these proxy settings will be used to contact the DoH server as well. However due to limitation of the library in use,
username and password information for the proxy are not supported. Also any per-job defined proxy settings in the
fetchHttp bean are not used when contacting the DoH server.
As the implementation relies on the corresponding client in the “dnsjava” library, which is currently labeled as experimental, this option comes with some limitations:
If you use Java 11 then due to a well known bug it will not close connections to the DoH server unless Heritrix shuts down. As the DoH server might not accept new connections after some limits while these connections are still open, it is not recommended to use this feature when running Heritrix with Java 11.
For other Java versions, the connection to the DoH server will be closed when the garbage collector runs. Depending on the garbage collector used this will cause a delay of anything between a few seconds and several minutes before closing the connection. Also note that if the garbage collector is explicitely triggered via the Heritrix UI one needs to add the
-XX:-DisableExplicitGCoption in theJAVA_OPTSfor Java versions 13 and up as otherwise this action has no effect.
Without making a recommendation the following DoH servers have been tested with the DoH feature:
However servers implementing the official RFC 8484 specification unfortunately do not work with the current implementation. This includes e.g. the following server:
This limitation might be overcome by a newer version of the “dnsjava” library.